2018 yılında yazdığım ve hala çokça ilgi gören makaleyi güncelleme zamanı geldi. Depolama dünyasındaki yenilikleri daha kapsamlı ve anlaşılır bir şekilde ele almak için bu seriyi üç kısma ayırarak paylaşacağım:
- 1. Kısım: IBM olarak geçmişte replikasyon ve yüksek erişilebilirlik (HA) senaryolarında neler yaptık?
- 2. Kısım: Politika bazlı replikasyon nedir? Hangi modları sunuyoruz, nasıl çalışıyor ve avantajları nelerdir?
- 3. Kısım: PBHA (Policy-Based High Availability) uygulamasını nasıl yapacağımızı kısa ve öz bir şekilde açıklayacağız.
İlk bölümde, yeniliklere geçmeden önce geçmişi hatırlayalım: Policy-Based Replication (Politika Bazlı Replikasyon) nedir? Hangi modlar sunuluyor? HA dışında başka hangi seçenekler mevcut? Bu sorulara yanıt vereceğiz.
Ayrıca, IBM Hyperswap yerine artık Policy-Based HA modelini sunuyoruz. Bu yeni modelin sunduğu avantajları, iş sürekliliği ve veri yönetiminde nasıl fark yaratacağını, kurulum sürecinin Hyperswap kadar kolay olduğunu bu seride adım adım ele alacağız.
Eskiden IBM Storage Virtualize’de synchronous replication (senkron replikasyon), Metro Mirror hizmetiyle sağlanıyordu. Ancak, coğrafi olarak uzak lokasyonlarda yüksek RTT (Round-Trip Time) nedeniyle bu yöntem pratik olmuyordu. (Görsel-1) Bu durumda asynchronous replication (asenkron replikasyon) devreye giriyordu.
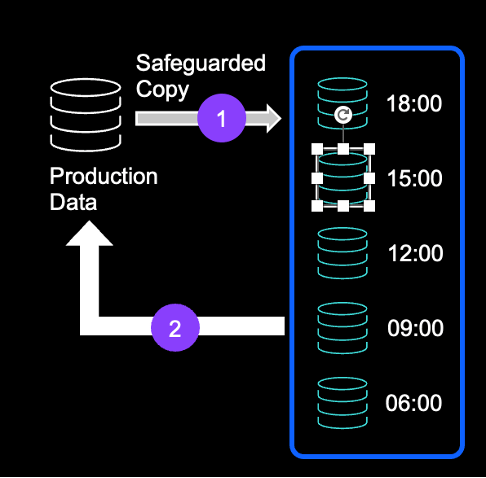
Asenkron modda, recovery site’daki veriler production site’ın gerisinde kalabiliyor, çünkü son cycle’dan sonra yapılan değişiklikler henüz aktarılmamış olabiliyor. Örneğin, Recovery Site “A” verisini işlerken Production “B” yazıyorsa, “B” ancak bir sonraki cycle’da recovery site’a ulaşıyor. (Görsel-2)
Bu eski versiyonlarda, asynchronous replication için iki temel hizmet kullanılıyordu:
- Global Mirror: Temel seviyede asenkron replikasyon sağlıyordu.
- Global Mirror with Change Volumes (cycling-mode): Snapshots kullanarak daha gelişmiş bir replikasyon yöntemi sunuyordu ve şu anki sistemle benzer bir mantıkla çalışıyordu.
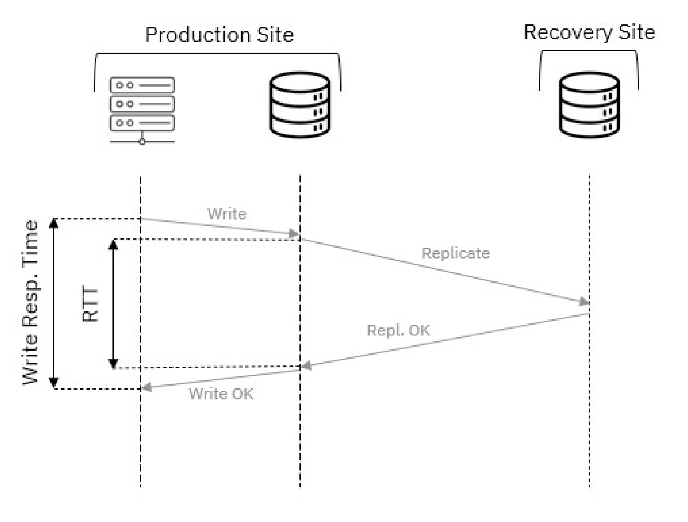
Görsel-1 – Senkron replikasyon ve RTT etkisi
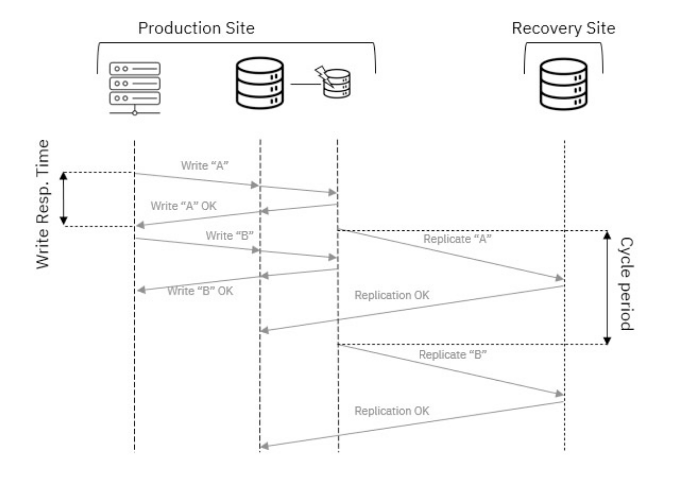
Görsel-2 – Döngü tabanlı asenkron replikasyon
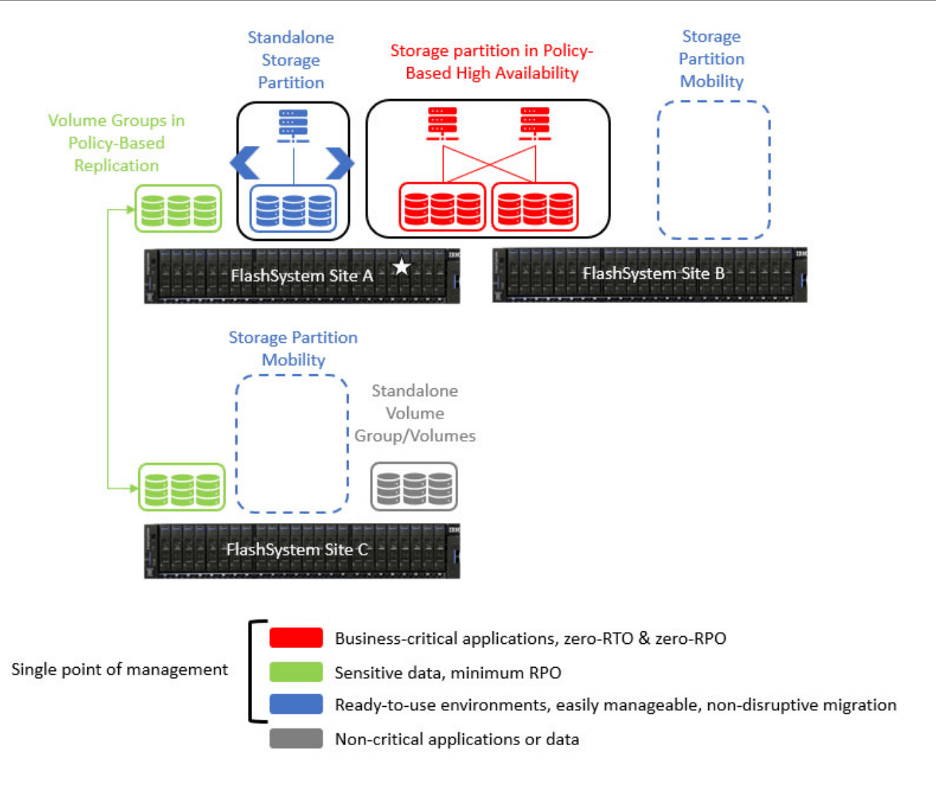
Serinin 2. kısmında yeni gelen Policy-based replication kısmını açıklayıp, içerisinde gelen Policy-based HA ile Hyperswap yerine iş sürekliliğini nasıl sağlıyoruz ona bakacağız.

Sıfır RPO ve sıfır RTO