OpenShift Virtualization İçin Yüksek Performanslı SAN Erişimi

Son zamanlarda konuştuğum müşterilerin büyük kısmında OpenShift Virtualization geçişinde en çok zorlayan konu storage performansı ve yönetimi oldu.
Birçok ekip, mevcut sanallaştırma yatırımlarını çöpe atmadan altyapılarını Kubernetes tabanlı platformlara taşımayı değerlendiriyor.
OpenShift Virtualization sayesinde kurumlar yalnızca container değil, mevcut sanal makinelerini de aynı platformda çalıştırabiliyor. VMware ortamlarından geçişte Migration Toolkit for Virtualization (MTV) kullanılarak VM’ler yeniden kurulum gerektirmeden taşınabiliyor. Hedef, sıfırdan mimari kurmak değil, kontrollü ve kademeli bir modernizasyon.
Bu geçiş projelerinde en kritik teknik konu genelde storage tarafı oluyor. VMware’de VM’ler doğrudan SAN LUN’ları üzerinde düşük gecikme ile çalışırken, OpenShift tarafında storage erişimi CSI katmanı üzerinden sağlanıyor. VM workloadlarının beklediği performansı yeni mimaride koruyabilmek burada önemli.
Bu noktada Fusion Access for SAN, OpenShift Virtualization üzerinde çalışan VM’lerin mevcut SAN’a düşük gecikmeli erişimini mümkün kılıyor.
VMware’e Benzer Çalışma Mantığı
Sahada en hızlı anlaşılan tarafı şu: davranışı VMFS modeline oldukça yakın.
VMware’de sanal makinalar paylaşımlı VMFS datastore üzerinde durur ve host’lar aynı LUN’a erişir. Migration sırasında veri yeniden yazılmaz.
Fusion Access mimarisinde de:
- SAN LUN’ları Storage Scale üzerinden paylaşımlı storage olarak sunulur,
- OpenShift worker node’lar aynı storage’a erişir,
- VM diskleri shared datastore mantığıyla çalışır,
- Live migration sırasında veri kopyalanmaz.
Bu yaklaşım pratikte daha düşük latency ve daha stabil IOPS anlamına geliyor. VMware’den geçiş yapan ekipler için operasyonel olarak da tanıdık bir model sunuyor.
Kapasite Verimliliği Avantajı
Fusion Access’in önemli bir farkı, ek bir storage replikasyon katmanı gerektirmemesi.
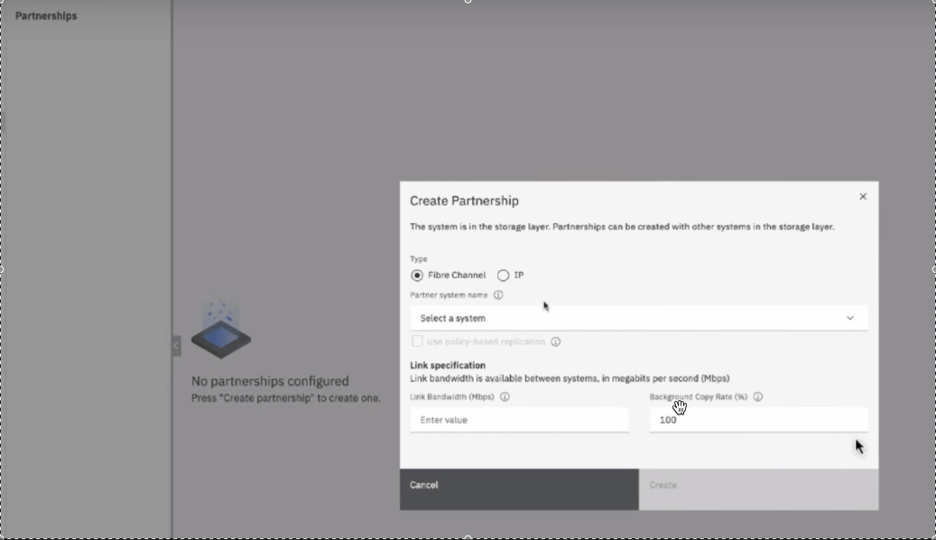
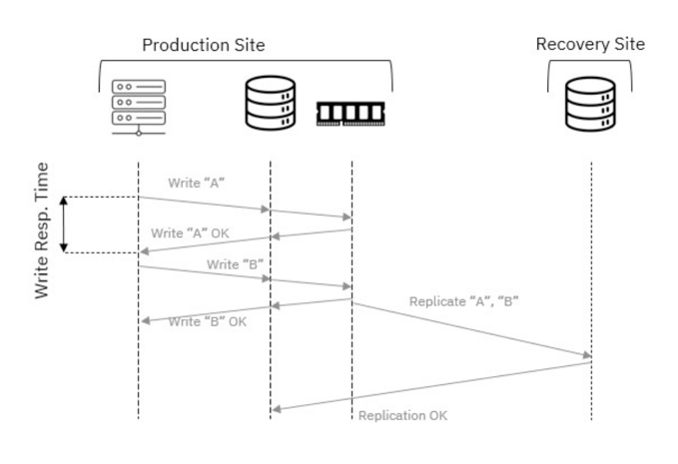
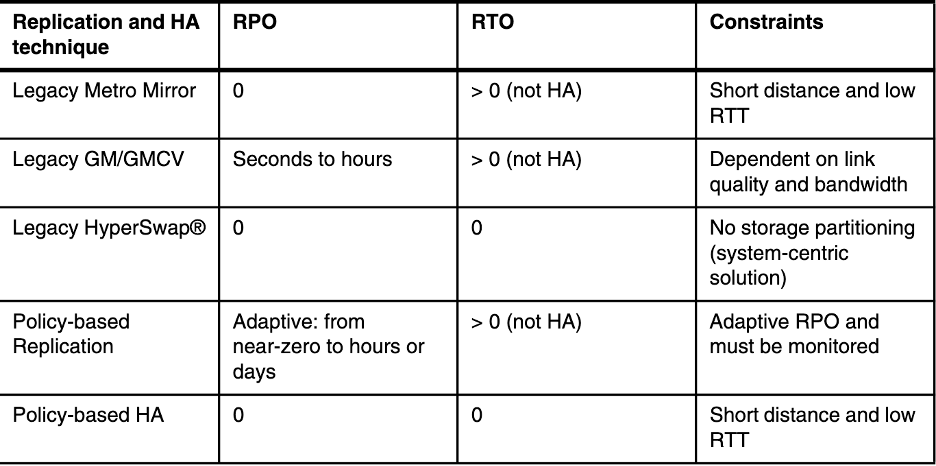
ODF gibi SDS çözümlerinde veri dayanıklılığı çoğunlukla, ilk görseldeki gibi
- 3x replication
- veya erasure coding
ile sağlanıyor. Bu güvenli bir yaklaşım fakat usable kapasiteyi düşürüyor ve özellikle flash katmanda maliyeti hızlı artırıyor.
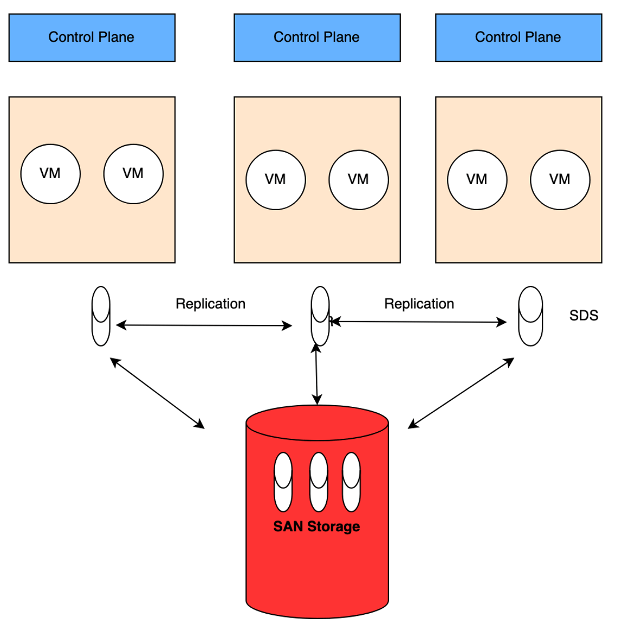
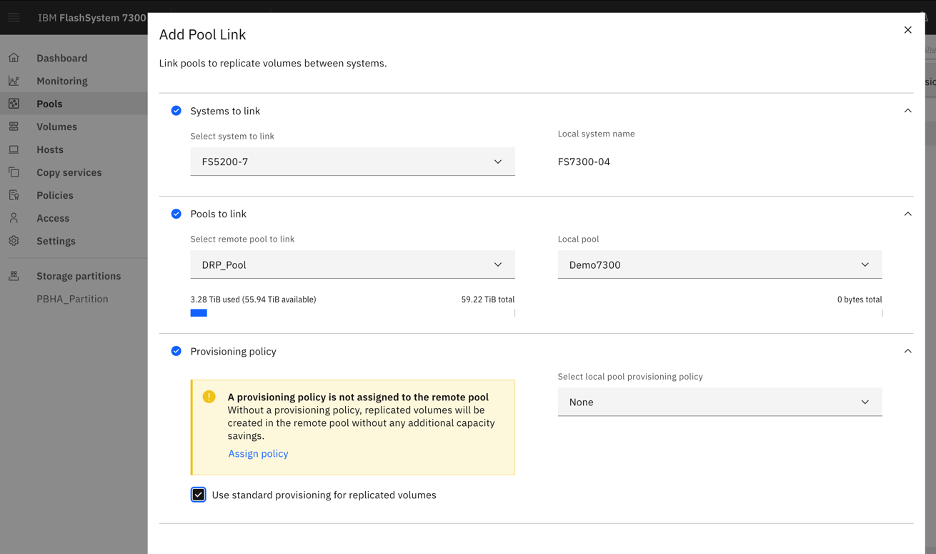
Fusion Access tarafında ise aşağıdaki 2. göseldeki gibi veri doğrudan mevcut enterprise storage üzerinde tutuluyor ve storage’ın kendi RAID veya replication mekanizmaları kullanılıyor. Cluster içinde ikinci bir kopya oluşturulmadığı için aynı usable kapasiteyi daha az disk ile sağlamak mümkün oluyor.
- Fusion Access Olmadan OpenShift Virtualization Ortamında Sık Görülen Problemler:
Fusion Access kullanılmadan kurulan OpenShift Virtualization ortamlarında sorun genelde compute ya da network’ten değil, storage katmanından çıkıyor. Sahada en sık gördüğüm başlıklar şunlar:
1. Beklenenden Yüksek Gecikme
VMware’de doğrudan SAN’a alışmış workload’lar, CSI üzerinden çalışan storage’da aynı tepki süresini veremeyebiliyor. Özellikle veritabanı tarafında hemen hissediliyor.
2. Stabil Olmayan IOPS
Container ve VM’ler aynı disk havuzunu paylaştığında IO dalgalanmaları oluşabiliyor. Kullanıcı tarafında “bazen hızlı, bazen yavaş” hissi oluşuyor.
3. Disklerin Hızlı Dolması
Replikasyon veya metadata overhead nedeniyle usable kapasite beklenenden hızlı tükenebiliyor. En sık duyulan cümle: “Bu kadar diski nasıl bu kadar çabuk doldurduk?”
4. Migration Sırasında Performans Etkisi
Paylaşımlı datastore mantığı güçlü değilse, VM taşınırken arka planda ekstra veri hareketi oluşabiliyor ve bu da storage ve network’e yük bindiriyor.
5. Kritik Workload’lar İçin Ayrı Performans Katmanı Oluşturamama
Hyperconverged yapılarda tüm iş yükleri aynı diskleri kullandığı için, yüksek IOPS isteyen uygulamaları izole etmek zorlaşıyor. Bir noktada ekipler yine “kritik işleri SAN’da tutalım” noktasına geliyor.
Sorun platform değil; VM’lerin alışık olduğu storage davranışını yeni mimaride aynı şekilde verememek.
Son olarak özetlemek gerekirse, Fusion Access aslında yeni bir storage kurmak değil, mevcut SAN performansını OpenShift dünyasına taşımak. VMware’den OpenShift’e geçmek teknik olarak zor değil, asıl zor olan storage performansını aynı seviyede tutmak.
Mevcutta Openshift Virtualization ortamı olanlar 60 günlük Fusion Access for SAN deneme hakkını alıp aşağıdaki linkten deployment sağlayabilir veya benimle iletişime geçerseniz destek olabiliriz.