Policy-based replication kısmını açıklayıp, içerisinde gelen Policy-based HA ile Hyperswap yerine iş sürekliliğini nasıl sağlıyoruz ona gelelim.
Policy-based replication üç çalışma moduna sahiptir:
- Change Recording mode: Production sistemi üzerindeki değişiklikleri izler ancak recovery sisteme çoğaltma yapmaz.
- Journaling mode: Production sistem üzerindeki değişiklikleri sırasıyla izler ve çoğaltır. ( Görsel 3)
- Cycling mode: Yeni host write işlemlerini izler ve production volume’un snapshot’ından periyodik olarak çoğaltır.
Journaling mode düşük RPO sağladığı için genelde ilk tercihtir, ancak bandwidth yetersizliği nedeniyle gereken write volume sağlanamazsa sistem otomatik olarak cycling mode‘a geçer. Bu modda, production volume’un periyodik snapshots‘ı alınır ve sadece yapılan değişiklikler çoğaltılır. Bu yaklaşım veri transferini azaltırken potansiyel veri kaybını biraz artırabilir. Cycle sıklığı, hedef RPO‘ya göre ayarlanır; daha sık cycle’lar veri kaybını azaltır ama daha fazla bandwidth gerektirir. Sistem bu dengeyi, belirlenen RPO‘yu karşılayacak şekilde otomatik olarak optimize eder.
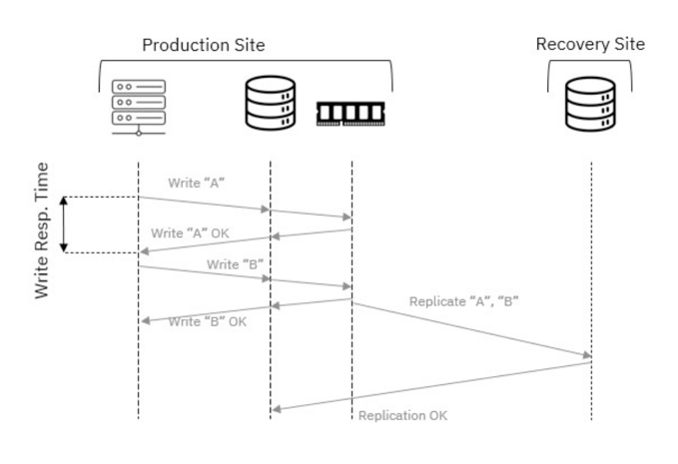
Görsel 3- Journaling mode ile politika tabanlı replikasyon
En büyük avantajlardan birisi bu yapı içerisinde, bir önceki FlashSystem Grid yazımda bahsettiğim Görsel-4’de tekrar görebileceğiniz partition mobilite ile farklı partitionları farklı modlarda kullanabilirsiniz.
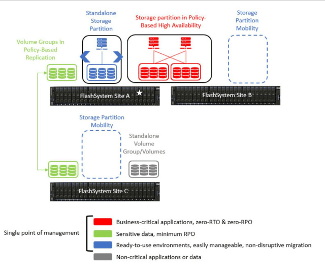
Görsel-4
Policy-based HA (PBHA), aktif/aktif çalışan bir yüksek erişilebilirlik çözümüdür. HA devredeyken, her iki volume kopyası da kullanılabilir ve host’lar I/O işlemlerini istediği kopyaya gönderebilir. Bu sırada kopyalar arasında tam senkronizasyon sağlanır.
Bu çözümde, synchronous replication kullanılarak üretim volume kopyaları arasında veri eşitliği korunur. Volume groups, birbiriyle bağlantılı uygulamalar arasında tutarlılığı yönetmek için kullanılır. Ayrıca, tüm site’lerden gelen host’ların aynı üretim verisine erişebilmesi gerekir. Bunun için IBM Storage Virtualize, Storage Partitions kavramını sunuyor. Storage Partitions, volume groups, host’lar ve mapping’lerden oluşan bir yapı olarak, tüm verinin organize ve erişilebilir olmasını sağlıyor. Görsel-5 e yapıyı daha iyi anlamak için bakabilirsiniz
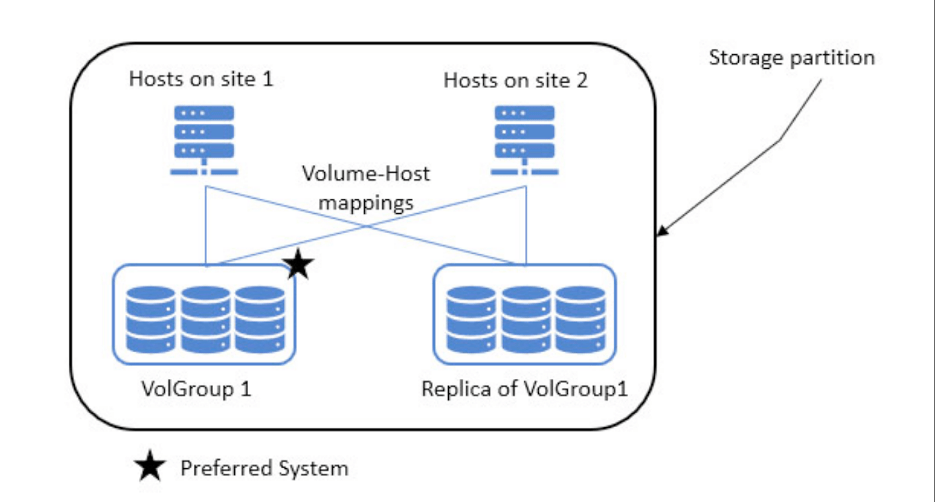
Görsel-5
Storage partitions sayesinde host’ları volume group kopyalarına manuel eşleştirmek gerekmez; her şey hazırdır. UID aynı olduğu için volume tanıma sorunları da yaşanmaz. HA, verilerin yanı sıra storage partition konfigürasyonlarını (host tanımları ve eşleştirmeler) da değişiklik olduğunda otomatik olarak uzak site’e aktarır.
Her partition için bir preferred management system seçilir; bu sistem, bağlantı kesilse bile yönetimin devamını sağlar. Host lokasyonları tanımlıysa, işlemler lokal olarak yapılır ve her site kendi verisine erişir. Bu düzenin sorunsuz işlemesi için host lokasyonlarının doğru yapılandırılmış olması önemlidir.
IBM Storage Virtualize’in policy-based replication özelliği, verileri recovery site’a kopyalayarak veri kaybını önler ve RPO‘yu minimum seviyeye indirir. Policy-based HA ise kesintisiz iş sürekliliği sağlar ve üretim sitesinden recovery site’a otomatik failover ile kesinti riskini ortadan kaldırır. Görsel-6 ya karşılaştırma tablosu için bakabilirsiniz.
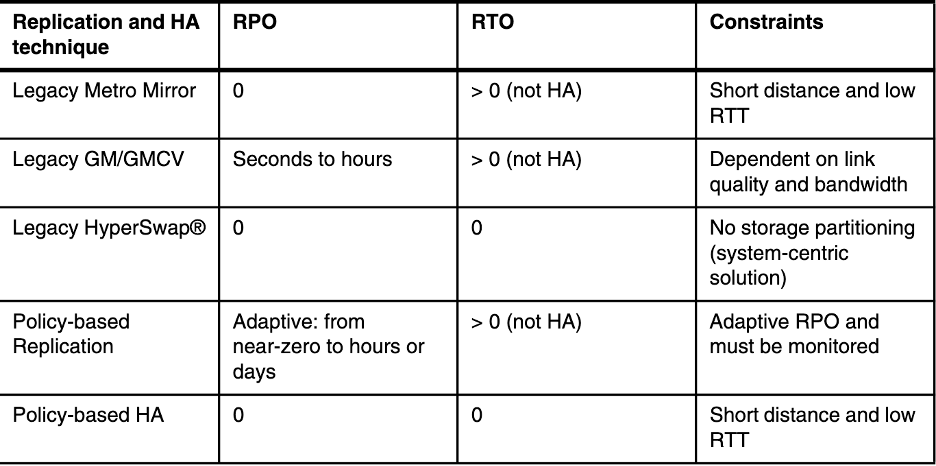
Görsel-6

Yorum bırakın